Clique (graph theory)
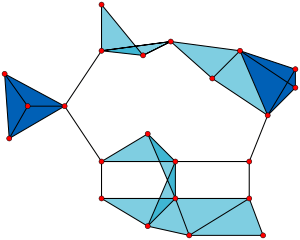
- 23 × 1-vertex cliques (the vertices),
- 42 × 2-vertex cliques (the edges),
- 19 × 3-vertex cliques (light and dark blue triangles), and
- 2 × 4-vertex cliques (dark blue areas).
In the mathematical area of graph theory, a clique (/ˈkliːk/ or /ˈklɪk/) is a subset of vertices of an undirected graph such that its induced subgraph is complete; that is, every two distinct vertices in the clique are adjacent. Cliques are one of the basic concepts of graph theory and are used in many other mathematical problems and constructions on graphs. Cliques have also been studied in computer science: the task of finding whether there is a clique of a given size in a graph (the clique problem) is NP-complete, but despite this hardness result, many algorithms for finding cliques have been studied.
Although the study of complete subgraphs goes back at least to the graph-theoretic reformulation of Ramsey theory by Erdős & Szekeres (1935),[1] the term clique comes from Luce & Perry (1949), who used complete subgraphs in social networks to model cliques of people; that is, groups of people all of whom know each other. Cliques have many other applications in the sciences and particularly in bioinformatics.
Definitions
A clique, C, in an undirected graph G = (V, E) is a subset of the vertices, C ⊆ V, such that every two distinct vertices are adjacent. This is equivalent to the condition that the induced subgraph of G induced by C is a complete graph. In some cases, the term clique may also refer to the subgraph directly.
A maximal clique is a clique that cannot be extended by including one more adjacent vertex, that is, a clique which does not exist exclusively within the vertex set of a larger clique. Some authors define cliques in a way that requires them to be maximal, and use other terminology for complete subgraphs that are not maximal.
A maximum clique of a graph, G, is a clique, such that there is no clique with more vertices.
The clique number ω(G) of a graph G is the number of vertices in a maximum clique in G.
The intersection number of G is the smallest number of cliques that together cover all edges of G.
The clique cover number of a graph G is the smallest number of cliques of G whose union covers V(G).
The opposite of a clique is an independent set, in the sense that every clique corresponds to an independent set in the complement graph. The clique cover problem concerns finding as few cliques as possible that include every vertex in the graph.
A related concept is a biclique, a complete bipartite subgraph. The bipartite dimension of a graph is the minimum number of bicliques needed to cover all the edges of the graph.
Mathematics
Mathematical results concerning cliques include the following.
- Turán's theorem (Turán 1941) gives a lower bound on the size of a clique in dense graphs. If a graph has sufficiently many edges, it must contain a large clique. For instance, every graph with vertices and more than edges must contain a three-vertex clique.
- Ramsey's theorem (Graham, Rothschild & Spencer 1990) states that every graph or its complement graph contains a clique with at least a logarithmic number of vertices.
- According to a result of Moon & Moser (1965), a graph with 3n vertices can have at most 3n maximal cliques. The graphs meeting this bound are the Moon–Moser graphs K3,3,..., a special case of the Turán graphs arising as the extremal cases in Turán's theorem.
- Hadwiger's conjecture, still unproven, relates the size of the largest clique minor in a graph (its Hadwiger number) to its chromatic number.
- The Erdős–Faber–Lovász conjecture is another unproven statement relating graph coloring to cliques.


Several important classes of graphs may be defined or characterized by their cliques:
- A cluster graph is a graph whose connected components are cliques.
- A block graph is a graph whose biconnected components are cliques.
- A chordal graph is a graph whose vertices can be ordered into a perfect elimination ordering, an ordering such that the neighbors of each vertex v that come later than v in the ordering form a clique.
- A cograph is a graph all of whose induced subgraphs have the property that any maximal clique intersects any maximal independent set in a single vertex.
- An interval graph is a graph whose maximal cliques can be ordered in such a way that, for each vertex v, the cliques containing v are consecutive in the ordering.
- A line graph is a graph whose edges can be covered by edge-disjoint cliques in such a way that each vertex belongs to exactly two of the cliques in the cover.
- A perfect graph is a graph in which the clique number equals the chromatic number in every induced subgraph.
- A split graph is a graph in which some clique contains at least one endpoint of every edge.
- A triangle-free graph is a graph that has no cliques other than its vertices and edges.
Additionally, many other mathematical constructions involve cliques in graphs. Among them,
- The clique complex of a graph G is an abstract simplicial complex X(G) with a simplex for every clique in G
- A simplex graph is an undirected graph κ(G) with a vertex for every clique in a graph G and an edge connecting two cliques that differ by a single vertex. It is an example of median graph, and is associated with a median algebra on the cliques of a graph: the median m(A,B,C) of three cliques A, B, and C is the clique whose vertices belong to at least two of the cliques A, B, and C.[2]
- The clique-sum is a method for combining two graphs by merging them along a shared clique.
- Clique-width is a notion of the complexity of a graph in terms of the minimum number of distinct vertex labels needed to build up the graph from disjoint unions, relabeling operations, and operations that connect all pairs of vertices with given labels. The graphs with clique-width one are exactly the disjoint unions of cliques.
- The intersection number of a graph is the minimum number of cliques needed to cover all the graph's edges.
- The clique graph of a graph is the intersection graph of its maximal cliques.
Closely related concepts to complete subgraphs are subdivisions of complete graphs and complete graph minors. In particular, Kuratowski's theorem and Wagner's theorem characterize planar graphs by forbidden complete and complete bipartite subdivisions and minors, respectively.
Computer science
In computer science, the clique problem is the computational problem of finding a maximum clique, or all cliques, in a given graph. It is NP-complete, one of Karp's 21 NP-complete problems (Karp 1972). It is also fixed-parameter intractable, and hard to approximate. Nevertheless, many algorithms for computing cliques have been developed, either running in exponential time (such as the Bron–Kerbosch algorithm) or specialized to graph families such as planar graphs or perfect graphs for which the problem can be solved in polynomial time.
Applications
The word "clique", in its graph-theoretic usage, arose from the work of Luce & Perry (1949), who used complete subgraphs to model cliques (groups of people who all know each other) in social networks. For continued efforts to model social cliques graph-theoretically, see e.g. Alba (1973), Peay (1974), and Doreian & Woodard (1994).
Many different problems from bioinformatics have been modeled using cliques. For instance, Ben-Dor, Shamir & Yakhini (1999) model the problem of clustering gene expression data as one of finding the minimum number of changes needed to transform a graph describing the data into a graph formed as the disjoint union of cliques; Tanay, Sharan & Shamir (2002) discuss a similar biclustering problem for expression data in which the clusters are required to be cliques. Sugihara (1984) uses cliques to model ecological niches in food webs. Day & Sankoff (1986) describe the problem of inferring evolutionary trees as one of finding maximum cliques in a graph that has as its vertices characteristics of the species, where two vertices share an edge if there exists a perfect phylogeny combining those two characters. Samudrala & Moult (1998) model protein structure prediction as a problem of finding cliques in a graph whose vertices represent positions of subunits of the protein. And by searching for cliques in a protein-protein interaction network, Spirin & Mirny (2003) found clusters of proteins that interact closely with each other and have few interactions with proteins outside the cluster. Power graph analysis is a method for simplifying complex biological networks by finding cliques and related structures in these networks.
In electrical engineering, Prihar (1956) uses cliques to analyze communications networks, and Paull & Unger (1959) use them to design efficient circuits for computing partially specified Boolean functions. Cliques have also been used in automatic test pattern generation: a large clique in an incompatibility graph of possible faults provides a lower bound on the size of a test set.[3] Cong & Smith (1993) describe an application of cliques in finding a hierarchical partition of an electronic circuit into smaller subunits.
In chemistry, Rhodes et al. (2003) use cliques to describe chemicals in a chemical database that have a high degree of similarity with a target structure. Kuhl, Crippen & Friesen (1983) use cliques to model the positions in which two chemicals will bind to each other.
Notes
- ↑ The earlier work by Kuratowski (1930) characterizing planar graphs by forbidden complete and complete bipartite subgraphs was originally phrased in topological rather than graph-theoretic terms.
- ↑ Barthélemy, Leclerc & Monjardet (1986), page 200.
- ↑ Hamzaoglu & Patel (1998).
References
- Alba, Richard D. (1973), "A graph-theoretic definition of a sociometric clique" (PDF), Journal of Mathematical Sociology, 3 (1): 113–126, doi:10.1080/0022250X.1973.9989826.
- Barthélemy, J.-P.; Leclerc, B.; Monjardet, B. (1986), "On the use of ordered sets in problems of comparison and consensus of classifications", Journal of Classification, 3 (2): 187–224, doi:10.1007/BF01894188.
- Ben-Dor, Amir; Shamir, Ron; Yakhini, Zohar (1999), "Clustering gene expression patterns.", Journal of Computational Biology, 6 (3–4): 281–297, doi:10.1089/106652799318274, PMID 10582567.
- Cong, J.; Smith, M. (1993), "A parallel bottom-up clustering algorithm with applications to circuit partitioning in VLSI design", Proc. 30th International Design Automation Conference, pp. 755–760, doi:10.1145/157485.165119.
- Day, William H. E.; Sankoff, David (1986), "Computational complexity of inferring phylogenies by compatibility", Systematic Zoology, 35 (2): 224–229, doi:10.2307/2413432, JSTOR 2413432.
- Doreian, Patrick; Woodard, Katherine L. (1994), "Defining and locating cores and boundaries of social networks", Social Networks, 16 (4): 267–293, doi:10.1016/0378-8733(94)90013-2.
- Erdős, Paul; Szekeres, George (1935), "A combinatorial problem in geometry" (PDF), Compositio Mathematica, 2: 463–470.
- Graham, R.; Rothschild, B.; Spencer, J. H. (1990), Ramsey Theory, New York: John Wiley and Sons, ISBN 0-471-50046-1.
- Hamzaoglu, I.; Patel, J. H. (1998), "Test set compaction algorithms for combinational circuits", Proc. 1998 IEEE/ACM International Conference on Computer-Aided Design, pp. 283–289, doi:10.1145/288548.288615.
- Karp, Richard M. (1972), "Reducibility among combinatorial problems", in Miller, R. E.; Thatcher, J. W., Complexity of Computer Computations (PDF), New York: Plenum, pp. 85–103.
- Kuhl, F. S.; Crippen, G. M.; Friesen, D. K. (1983), "A combinatorial algorithm for calculating ligand binding", Journal of Computational Chemistry, 5 (1): 24–34, doi:10.1002/jcc.540050105.
- Kuratowski, Kazimierz (1930), "Sur le probléme des courbes gauches en Topologie" (PDF), Fundamenta Mathematicae (in French), 15: 271–283.
- Luce, R. Duncan; Perry, Albert D. (1949), "A method of matrix analysis of group structure", Psychometrika, 14 (2): 95–116, doi:10.1007/BF02289146, PMID 18152948.
- Moon, J. W.; Moser, L. (1965), "On cliques in graphs", Israel J. Math., 3: 23–28, doi:10.1007/BF02760024, MR 0182577.
- Paull, M. C.; Unger, S. H. (1959), "Minimizing the number of states in incompletely specified sequential switching functions", IRE Trans. on Electronic Computers, EC–8 (3): 356–367, doi:10.1109/TEC.1959.5222697.
- Peay, Edmund R. (1974), "Hierarchical clique structures", Sociometry, 37 (1): 54–65, doi:10.2307/2786466, JSTOR 2786466.
- Prihar, Z. (1956), "Topological properties of telecommunications networks", Proceedings of the IRE, 44 (7): 927–933, doi:10.1109/JRPROC.1956.275149.
- Rhodes, Nicholas; Willett, Peter; Calvet, Alain; Dunbar, James B.; Humblet, Christine (2003), "CLIP: similarity searching of 3D databases using clique detection", Journal of Chemical Information and Computer Sciences, 43 (2): 443–448, doi:10.1021/ci025605o, PMID 12653507.
- Samudrala, Ram; Moult, John (1998), "A graph-theoretic algorithm for comparative modeling of protein structure", Journal of Molecular Biology, 279 (1): 287–302, doi:10.1006/jmbi.1998.1689, PMID 9636717.
- Spirin, Victor; Mirny, Leonid A. (2003), "Protein complexes and functional modules in molecular networks", Proceedings of the National Academy of Sciences, 100 (21): 12123–12128, doi:10.1073/pnas.2032324100, PMC 218723
 , PMID 14517352.
, PMID 14517352. - Sugihara, George (1984), "Graph theory, homology and food webs", in Levin, Simon A., Population Biology, Proc. Symp. Appl. Math., 30, pp. 83–101.
- Tanay, Amos; Sharan, Roded; Shamir, Ron (2002), "Discovering statistically significant biclusters in gene expression data", Bioinformatics, 18 (Suppl. 1): S136–S144, doi:10.1093/bioinformatics/18.suppl_1.S136, PMID 12169541.
- Turán, Paul (1941), "On an extremal problem in graph theory", Matematikai és Fizikai Lapok (in Hungarian), 48: 436–452