Synchronization (computer science)
In computer science, synchronization refers to one of two distinct but related concepts: synchronization of processes, and synchronization of data. Process synchronization refers to the idea that multiple processes are to join up or handshake at a certain point, in order to reach an agreement or commit to a certain sequence of action. Data synchronization refers to the idea of keeping multiple copies of a dataset in coherence with one another, or to maintain data integrity. Process synchronization primitives are commonly used to implement data synchronization.[1]
The need for synchronization
The need for synchronization does not arise merely in multi-processor systems but for any kind of concurrent processes; even in single processor systems. Mentioned below are some of the main needs for synchronization:
Forks and Joins: When a job arrives at a fork point, it is split into N sub-jobs which are then serviced by n tasks. After being serviced, each sub-job waits until all other sub-jobs are done processing. Then, they are joined again and leave the system. Thus, in parallel programming ,we require synchronization as all the parallel process wait for several other processes to occur.
Producer-Consumer: In a producer-consumer relationship, the consumer process is dependent on the producer process till the necessary data has been produced.
Exclusive use resources: When multiple processes are dependent on a resource and they need to access it at the same time the operating system needs to ensure that only one processor accesses it at a given point in time.This reduces concurrency.
Thread or process synchronization
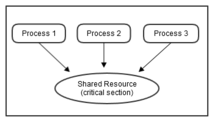
Thread synchronization is defined as a mechanism which ensures that two or more concurrent processes or threads do not simultaneously execute some particular program segment known as critical section. Processes' access to critical section is controlled by using synchronization techniques. When one thread starts executing the critical section (serialized segment of the program) the other thread should wait until the first thread finishes. If proper synchronization techniques[2] are not applied, it may cause a race condition where the values of variables may be unpredictable and vary depending on the timings of context switches of the processes or threads.
For example, suppose that there are three processes namely, 1, 2 and 3. All three of them are concurrently executing and they need to share a common resource (critical section) as shown in Figure 1. Synchronization should be used here to avoid any conflicts for accessing this shared resource. Hence, when Process 1 and 2 both try to access that resource it should be assigned to only one process at a time. If it is assigned to Process 1, the other process (Process 2) needs to wait until Process 1 frees that resource (as shown in Figure 2).
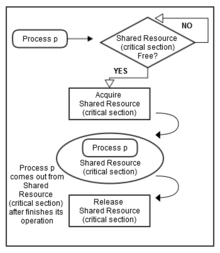
Another synchronization requirement which needs to be considered is the order in which particular processes or threads should be executed. For example, we cannot board a plane until we buy a ticket. Similarly, we cannot check emails without validating our credentials (i.e., user name and password). In the same way, an ATM will not provide any service until we provide it with a correct PIN.
Other than mutual exclusion, synchronization also deals with the following:
- deadlock, which occurs when many processes are waiting for a shared resource (critical section) which is being held by some other process. In this case the processes just keep waiting and execute no further;
- starvation, which occurs when a process is waiting to enter the critical section but other processes monopolize the critical section and the first process is forced to wait indefinitely;
- priority inversion, which occurs when a high priority process is in the critical section, it may be interrupted by a medium priority process. This violation of priority rules can happen under certain circumstances and may lead to serious consequences in real-time systems;
- busy waiting, which occurs when a process frequently polls to determine if it has access to a critical section. This frequent polling robs processing time from other processes.
Classic problems of synchronization
The following are some classic problems of synchronization:
- The Producer–Consumer Problem (also called The Bounded Buffer Problem);
- The Readers–Writers Problem;
- The Dining Philosophers Problem.
These problems are used to test nearly every newly proposed synchronization scheme or primitive.
Hardware synchronization
Many systems provide hardware support for critical section code.
A single processor or uniprocessor system could disable interrupts by executing currently running code without preemption, which is very inefficient on multiprocessor systems.[3] "The key ability we require to implement synchronization in a multiprocessor is a set of hardware primitives with the ability to atomically read and modify a memory location. Without such a capability, the cost of building basic synchronization primitives will be too high and will increase as the processor count increases. There are a number of alternative formulations of the basic hardware primitives, all of which provide the ability to atomically read and modify a location, together with some way to tell if the read and write were performed atomically. These hardware primitives are the basic building blocks that are used to build a wide variety of user-level synchronization operations, including things such as locks and barriers. In general, architects do not expect users to employ the basic hardware primitives, but instead expect that the primitives will be used by system programmers to build a synchronization library, a process that is often complex and tricky."[4] Many modern hardware provides special atomic hardware instructions by either test-and-set the memory word or compare-and-swap contents of two memory words.
Synchronization strategies in programming languages
In Java, to prevent thread interference and memory consistency errors, blocks of code are wrapped into synchronized (lock_object) sections. This forces any thread to acquire the said lock object before it can execute the block. The lock is automatically released when thread leaves the block or enter the waiting state within the block. Any variable updates, made by the thread in synchronized block, become visible to other threads whenever those other threads similarly acquires the lock.
In addition to mutual exclusion and memory consistency, Java synchronized blocks enable signaling, sending events from those threads, which have acquired the lock and execute the code block to those which are waiting for the lock within the block. This means that Java synchronized sections combine functionality of mutexes and events. Such primitive is known as synchronization monitor.
Any object is fine to be used as a lock/monitor in Java. The declaring object is implicitly implied as lock object when the whole method is marked with synchronized.
The .NET framework has synchronization primitives. "Synchronization is designed to be cooperative, demanding that every thread or process follow the synchronization mechanism before accessing protected resources (critical section) for consistent results." In .NET, locking, signaling, lightweight synchronization types, spinwait and interlocked operations are some of mechanisms related to synchronization.[5]
Implementation of Synchronization
Spinlock
Another effective way of implementing sychronization is by using spinlocks. Before accessing any shared resource or piece of code, every processor checks a flag. If the flag is reset, then the processor sets the flag and continues executing the thread. But, if the flag is set(locked), the threads would keep spinning in a loop and keep checking if the flag is set or not. But, spinlocks are effective only if the flag is reset for lower cycles otherwise it can lead to performance issues as it wastes many processor cycles waiting.[6]
Barriers
Barriers are simple to implement and provide good responsiveness. They are based on the concept of implementing wait cycles to provide synchronization.Consider three threads running simultaneously, starting from barrier 1. After time t, thread1 reaches barrier 2 but it still has to wait for thread 2 and 3 to reach barrier2 as it does not have the correct data. Once, all the threads reach barrier 2 they all start again. After time t, thread 1 reaches barrier3 but it will have to wait for threads 2 and 3 and the correct data again.
Thus, in barrier synchronization of multiple threads there will always be a few threads that will end up waiting for other threads as in the above example thread 1 keeps waiting for thread 2 and 3. This results in severe degradation of the process performance.[7]
The barrier synchronization wait function for ith thread can be represented as:
(Wbarrier)i = f ((Tbarrier)i, (Rthread)i)
Where Wbarrier is the wait time for a thread, Tbarrier is the number of threads has arrived, and Rthread is the arrival rate of threads.[8]
Experiments show that 34% of the total execution time is spent in waiting for other slower threads.[7]
Semaphores
Semaphores are signalling mechanisms which can allow one or more threads/processors to access a section. A Semaphore has a flag which has a certain fixed value associated with it and each time a thread wishes to access the section, it decrements the flag. Similarly, when the thread leaves the section, the flag is incremented. If the flag is zero, the thread cannot access the section and gets blocked if it chooses to wait.
Some semaphores would allow only one thread or process in the code section. Such Semaphores are called binary semaphore and are very similar to Mutex. Here, if the value of semaphore is 1, the thread is allowed to access and if the value is 0, the access is denied.[9]
Mathematical foundations
Synchronization was originally a process-based concept whereby a lock could be obtained on an object. Its primary usage was in databases. There are two types of (file) lock; read-only and read–write. Read-only locks may be obtained by many processes or threads. Readers–writer locks are exclusive, as they may only be used by a single process/thread at a time.
Although locks were derived for file databases, data is also shared in memory between processes and threads. Sometimes more than one object (or file) is locked at a time. If they are not locked simultaneously they can overlap, causing a deadlock exception.
Java and Ada only have exclusive locks because they are thread based and rely on the compare-and-swap processor instruction.
An abstract mathematical foundation for synchronization primitives is given by the history monoid. There are also many higher-level theoretical devices, such as process calculi and Petri nets, which can be built on top of the history monoid.
Synchronization examples
Following are some synchronization examples with respect to different platforms.[10]
Synchronization in Windows
Windows provides:
- interrupt masks, which protect access to global resources (critical section) on uniprocessor systems;
- spinlocks, which prevent, in multiprocessor systems, spinlocking-thread from being preempted;
- dispatchers, which act like mutexes, semaphores, events, and timers.
Synchronization in Linux
Linux provides:
- semaphores;
- spinlocks;
- readers–writer locks, for the longer section of codes which are accessed very frequently but don't change very often.
Enabling and disabling of kernel preemption replaced spinlocks on uniprocessor systems. Prior to kernel version 2.6, Linux disabled interrupt to implement short critical sections. Since version 2.6 and later, Linux is fully preemptive.
Synchronization in Solaris
Solaris provides:
- semaphores;
- condition variables;
- adaptive mutexes, binary semaphores that are implemented differently depending upon the conditions;
- readers–writer locks:
- turnstiles, queue of threads which are waiting on acquired lock.
Pthreads synchronization
Pthreads is a platform-independent API that provides:
- mutexes;
- condition variables;
- readers–writer locks;
- spinlocks;
- barriers.
Data synchronization
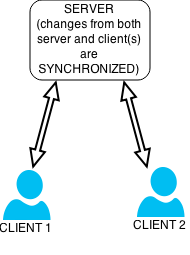
A distinctly different (but related) concept is that of data synchronization. This refers to the need to keep multiple copies of a set of data coherent with one another or to maintain data integrity, Figure 3. For example, database replication is used to keep multiple copies of data synchronized with database servers that store data in different locations.
Examples include:
- File synchronization, such as syncing a hand-held MP3 player to a desktop computer;
- Cluster file systems, which are file systems that maintain data or indexes in a coherent fashion across a whole computing cluster;
- Cache coherency, maintaining multiple copies of data in sync across multiple caches;
- RAID, where data is written in a redundant fashion across multiple disks, so that the loss of any one disk does not lead to a loss of data;
- Database replication, where copies of data on a database are kept in sync, despite possible large geographical separation;
- Journaling, a technique used by many modern file systems to make sure that file metadata are updated on a disk in a coherent, consistent manner.
Challenges in data synchronization
Some of the challenges which user may face in data synchronization:
- data formats complexity;
- real-timeliness;
- data security;
- data quality;
- performance.
Data formats complexity
When we start doing something, the data we have usually is in a very simple format. It varies with time as the organization grows and evolves and results not only in building a simple interface between the two applications (source and target), but also in a need to transform the data while passing them to the target application. ETL (extraction transformation loading) tools can be very helpful at this stage for managing data format complexities..
Real-timeliness
This is an era of real-time systems. Customers want to see the current status of their order in e-shop, the current status of a parcel delivery—a real time parcel tracking—, the current balance on their account, etc. This shows the need of a real-time system, which is being updated as well to enable smooth manufacturing process in real-time, e.g., ordering material when enterprise is running out stock, synchronizing customer orders with manufacturing process, etc. From real life, there exist so many examples where real-time processing gives successful and competitive advantage.
Data security
There are no fixed rules and policies to enforce data security. It may vary depending on the system which you are using. Even though the security is maintained correctly in the source system which captures the data, the security and information access privileges must be enforced on the target systems as well to prevent any potential misuse of the information. This is a serious issue and particularly when it comes for handling secret, confidential and personal information. So because of the sensitivity and confidentiality, data transfer and all in-between information must be encrypted.
Data quality
Data quality is another serious constraint. For better management and to maintain good quality of data, the common practice is to store the data at one location and share with different people and different systems and/or applications from different locations. It helps in preventing inconsistencies in the data.
Performance
There are five different phases involved in the data synchronization process:
- data extraction from the source (or master, or main) system;
- data transfer;
- data transformation;
- data load to the target system.
Each of these steps is very critical. In case of large amounts of data, the synchronization process needs to be carefully planned and executed to avoid any negative impact on performance.
See also
- Futures and promises, synchronization mechanisms in pure functional paradigms
References
- ↑ William, Stallings (2012). Operating Systems. Content Technologies, Inc.
- ↑ Gramoli, V. (2015). More than you ever wanted to know about synchronization: Synchrobench, measuring the impact of the synchronization on concurrent algorithms (PDF). Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. ACM. pp. 1–10.
- ↑ Silberschatz, Abraham; Gagne, Greg; Galvin, Peter Baer (July 11, 2008). "Chapter 6: Process Synchronization". Operating System Concepts (Eighth ed.). John Wiley & Sons. ISBN 978-0-470-12872-5.
- ↑ Hennessy, John L.; Patterson, David A. (September 30, 2011). "Chapter 5: Thread-Level Parallelism". Computer Architecture: A Quantitative Approach (Fifth ed.). Morgan Kaufmann. ISBN 978-0-123-83872-8.
- ↑ "Synchronization Primitives in .NET framework". MSDN, The Microsoft Developer Network. Microsoft. Retrieved 23 November 2014.
- ↑ Massa, Anthony (2003). Embedded Software Development with ECos. Pearson Education Inc. ISBN 0- 13-035473-2.
- 1 2 Meng, Chen, Pan, Yao, Wu, Jinglei, Tianzhou, Ping, Jun. Minghui (2014). "A speculative mechanism for barrier sychronization". 2014 IEEE International Conference on High Performance Computing and Communications (HPCC), 2014 IEEE 6th International Symposium on Cyberspace Safety and Security (CSS) and 2014 IEEE 11th International Conference on Embedded Software and Systems (ICESS).
- ↑ M. M., Rahman (2012). "Process synchronization in multiprocessor and multi-core processor". Informatics, Electronics & Vision (ICIEV), 2012 International Conference. doi:10.1109/ICIEV.2012.6317471.
- ↑ Li, Yao, Qing, Carolyn (2003). Real-Time Concepts for Embedded Systems. CMP Books. ISBN 1578201241.
- ↑ Silberschatz, Abraham; Gagne, Greg; Galvin, Peter Baer (December 7, 2012). "Chapter 5: Process Synchronization". Operating System Concepts (Ninth ed.). John Wiley & Sons. ISBN 978-1-118-06333-0.
- Schneider, Fred B. (1997). On concurrent programming. Springer-Verlag New York, Inc. ISBN 0-387-94942-9.
External links
- Anatomy of Linux synchronization methods at IBM developerWorks
- The Little Book of Semaphores, by Allen B. Downey
| General | |
|---|---|
| Levels | |
| Multithreading | |
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |