P-Grid
In distributed data storage, a P-Grid is a self-organizing structured peer-to-peer system, which can accommodate arbitrary key distributions (and hence support lexicographic key ordering and range queries), still providing storage load-balancing and efficient search by using randomized routing.
Salient features
- Good storage load-balancing despite arbitrary load-distribution over the key-space.
- Range queries can be naturally supported and efficiently processed on P-Grid because P-Grid abstracts a trie-structure, and supports (rather) arbitrary distribution of keys, as observed in realistic scenarios.
- A Self-referential directory is realized to provide peer identity persistence over multiple sessions.
- A gossip primitive based update mechanism for keeping replicated content up-to-date.
- Easy merger of multiple P-Grids, and hence decentralized bootstrapping of the P-Grid network.
- Query-adaptive caching is easy to realize on P-Grid to provide query load-balancing where peers have restricted capacity.
Overview
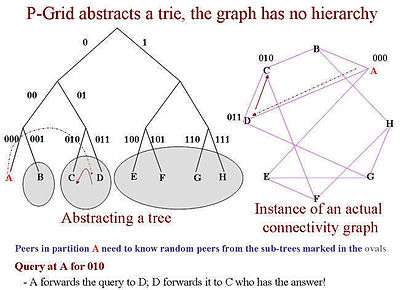
P-Grid abstracts a trie and resolves queries based on prefix matching. The actual topology has no hierarchy. Queries are resolved by matching prefixes. This also determines the choice of routing table entries. Each peer, for each level of the trie, maintains autonomously routing entries chosen randomly from the complementary sub-trees. In fact, multiple entries are maintained for each level at each peer to provide fault-tolerance (as well as potentially for query-load management). For diverse reasons including fault-tolerance and load-balancing, multiple peers are responsible for each leaf node in the P-Grid tree. These are called replicas. The replica peers maintain an independent replica sub-network and uses gossip based communication to keep the replica group up-to-date. The redundancy in both the replication of key-space partitions as well as the routing network together is called structural replication. The figure below shows how a query is resolved by forwarding it based on prefix matching.
Range queries in P-grid
P-Grid partitions the key-space in a granularity adaptive to the load at that part of the key-space. Consequently, its possible to realize a P-Grid overlay network where each peer has similar storage load even for non-uniform load distributions. This network probably provides as efficient search of keys as traditional distributed hash tables (DHTs) do. Note that in contrast to P-Grid, DHTs work efficiently only for uniform load-distributions.
Hence we can use a lexicographic order preserving function to generate the keys, and still realize a load-balanced P-Grid network which supports efficient search of exact keys. Moreover, because of the preservation of lexicographic ordering, range queries can be done efficiently and precisely on P-Grid. The trie-structure of P-Grid allows different range query strategies, processed serially or parallelly, trading off message overheads and query resolution latency.