Neurocomputational speech processing
Neurocomputational speech processing is computer-simulation of speech production and speech perception by referring to the natural neuronal processes of speech production and speech perception, as they occur in the human nervous system (central nervous system and peripheral nervous system). This topic is based on neuroscience and computational neuroscience.[1]
Overview
Neurocomputational models of speech processing are complex. They comprise at least a cognitive part, a motor part and a sensory part.
The cognitive or linguistic part of a neurocomputational model of speech processing comprises the neural activation or generation of a phonemic representation on the side of speech production (e.g. neurocomputational and extended version of the Levelt model developed by Ardi Roelofs:[2] WEAVER++[3] as well as the neural activation or generation of an intention or meaning on the side of speech perception or speech comprehension.
The motor part of a neurocomputational model of speech processing starts with a phonemic representation of a speech item, activates a motor plan and ends with the articulation of that particular speech item (see also: articulatory phonetics).
The sensory part of a neurocomputational model of speech processing starts with an acoustic signal of a speech item (acoustic speech signal), generates an auditory representation for that signal and activates a phonemic representations for that speech item.
Neurocomputational speech processing topics
Neurocomputational speech processing is speech processing by artificial neural networks. Neural maps, mappings and pathways as described below, are model structures, i.e. important structures within artificial neural networks.
Neural maps

A neural network can be separated in three types of neural maps, also called "layers":
- input maps (in the case of speech processing: primary auditory map within the auditory cortex, primary somatosensory map within the somatosensory cortex),
- output maps (primary motor map within the primary motor cortex), and
- higher level cortical maps (also called "hidden layers", see neural networks).
The term "neural map" is favoured here over the term "neural layer", because a cortial neural map should be modeled as a 2D-map of interconnected neurons (e.g. like a self-organizing map; see also Fig. 1). Thus, each "model neuron" or "artificial neuron" within this 2D-map is physiologically represented by a cortical column since the cerebral cortex anatomically exhibits a layered structure.
Neural representations (neural states)
A neural representation within an artificial neural network is a temporarily activated (neural) state within a specific neural map. Each neural state is represented by a specific neural activation pattern. This activation pattern changes during speech processing (e.g. from syllable to syllable).

In the ACT model (see below), it is assumed that an auditory state can be represented by a "neural spectrogram" (see Fig. 2) within an auditory state map. This auditory state map is assumed to be located in the auditory association cortex (see cerebral cortex).
A somatosensory state can be divided in a tactile and proprioceptive state and can be represented by a specific neural activation pattern within the somatosensory state map. This state map is assumed to be located in the somatosensory association cortex (see cerebral cortex, somatosensory system, somatosensory cortex).
A motor plan state can be assumed for representing a motor plan, i.e. the planning of speech articulation for a specific syllable or for a longer speech item (e.g. word, short phrase). This state map is assumed to be located in the premotor cortex, while the instantaneous (or lower level) activation of each speech articulator occurs within the primary motor cortex (see motor cortex).
The neural representations occurring in the sensory and motor maps (as introduced above) are distributed representations (Hinton et al. 1968[4]): Each neuron within the sensory or motor map is more or less activated, leading to a specific activation pattern.
The neural representation for speech units occurring in the speech sound map (see below: DIVA model) is a punctual or local representation. Each speech item or speech unit is represented here by a specific neuron (model cell, see below).
Neural mappings (synaptic projections)

A neural mapping connects two cortical neural maps. Neural mappings (in contrast to neural pathways) store training information by adjusting their neural link weights (see artificial neuron, artificial neural networks). Neural mappings are capable of generating or activating a distributed representation (see above) of a sensory or motor state within a sensory or motor map from a punctual or local activation within the other map (see for example the synaptic projection from speech sound map to motor map, to auditory target region map, or to somatosensory target region map in the DIVA model, explained below; or see for example the neural mapping from phonetic map to auditory state map and motor plan state map in the ACT model, explained below and Fig. 3).
Neural mapping between two neural maps are compact or dense: Each neuron of one neural map is interconnected with (nearly) each neuron of the other neural map (many-to-many-connection, see artificial neural networks). Because of this density criterion for neural mappings, neural maps which are interconnected by a neural mapping are not far apart from each other.
Neural pathways
In contrast to neural mappings neural pathways can connect neural maps which are far apart (e.g. in different cortical lobes, see cerebral cortex). From the functional or modeling viewpoint, neural pathways mainly forward information without processing this information. A neural pathway in comparison to a neural mapping need much less neural connections. A neural pathway can be modelled by using a one-to-one connection of the neurons of both neural maps (see topographic mapping and see somatotopic arrangement).
Example: In the case of two neural maps, each comprising 1,000 model neurons, a neural mapping needs up to 1,000,000 neural connections (many-to-many-connection), while only 1,000 connections are needed in the case of a neural pathway connection.
Furthermore the link weights of the connections within a neural mapping are adjusted during training, while the neural connections in the case of a neural pathway need not to be trained (each connection is maximal exhibitory).
DIVA model
The leading approach in neurocomputational modeling of speech production is the DIVA model developed by Frank H. Guenther and his group at Boston University.[5][6][7][8] The model accounts for a wide range of phonetic and neuroimaging data but - like each neurocomputational model - remains speculative to some extent.
Structure of the model

The organization or structure of the DIVA model is shown in Fig. 4.
Speech sound map: the phonemic representation as a starting point
The speech sound map - assumed to be located in the inferior and posterior portion of Broca's area (left frontal operculum) - represents (phonologically specified) language-specific speech units (sounds, syllables, words, short phrases). Each speech unit (mainly syllables; e.g. the syllable and word "palm" /pam/, the syllables /pa/, /ta/, /ka/, ...) is represented by a specific model cell within the speech sound map (i.e. punctual neural representations, see above). Each model cell (see artificial neuron) corresponds to a small population of neurons which are located at close range and which fire together.
Feedforward control: activating motor representations
Each neuron (model cell, artificial neuron) within the speech sound map can be activated and subsequently activates a forward motor command towards the motor map, called articulatory velocity and position map. The activated neural representation on the level of that motor map determines the articulation of a speech unit, i.e. controls all articulators (lips, tongue, velum, glottis) during the time interval for producing that speech unit. Forward control also involves subcortical structures like the cerebellum, not modelled in detail here.
A speech unit represents an amount of speech items which can be assigned to the same phonemic category. Thus, each speech unit is represented by one specific neuron within the speech sound map, while the realization of a speech unit may exhibit some articulatory and acoustic variability. This phonetic variability is the motivation to define sensory target regions in the DIVA model (see Guenther et al. 1998[9]).
Articulatory model: generating somatosensory and auditory feedback information
The activation pattern within the motor map determines the movement pattern of all model articulators (lips, tongue, velum, glottis) for a speech item. In order not to overload the model, no detailed modeling of the neuromuscular system is done. The Maeda articulatory speech synthesizer is used in order to generate articulator movements, which allows the generation of a time-varying vocal tract form and the generation of the acoustic speech signal for each particular speech item.
In terms of artificial intelligence the articulatory model can be called plant (i.e. the system, which is controlled by the brain); it represents a part of the embodiement of the neuronal speech processing system. The articulatory model generates sensory output which is the basis for generating feedback information for the DIVA model (see below: feedback control).
Feedback control: sensory target regions, state maps, and error maps
On the one hand the articulatory model generates sensory information, i.e. an auditory state for each speech unit which is neurally represented within the auditory state map (distributed representation), and a somatosensory state for each speech unit which is neurally represented within the somatosensory state map (distributed representation as well). The auditory state map is assumed to be located in the superior temporal cortex while the somatosensory state map is assumed to be located in the inferior parietal cortex.
On the other hand the speech sound map, if activated for a specific speech unit (single neuron activation; punctual activation), activates sensory information by synaptic projections between speech sound map and auditory target region map and between speech sound map and somatosensory target region map. Auditory and somatosensory target regions are assumed to be located in higher-order auditory cortical regions and in higher-order somatosensory cortical regions respectively. These target region sensory activation patterns - which exist for each speech unit - are learned during speech acquisition (by imitation training; see below: learning).
Consequently two types of sensory information are available if a speech unit is activated at the level of the speech sound map: (i) learned sensory target regions (i.e. intended sensory state for a speech unit) and (ii) sensory state activation patterns resulting from a possibly imperfect execution (articulation) of a specific speech unit (i.e. current sensory state, reflecting the current production and articulation of that particular speech unit). Both types of sensory information is projected to sensory error maps, i.e. to an auditory error map which is assumed to be located in the superior temporal cortex (like the auditory state map) and to a somatosensosry error map which is assumed to be located in the inferior parietal cortex (like the somatosensory state map) (see Fig. 4).
If the current sensory state deviates from the intended sensory state, both error maps are generating feedback commands which are projected towards the motor map and which are capable to correct the motor activation pattern and subsequently the articulation of a speech unit under production. Thus, in total, the activation pattern of the motor map is not only influenced by a specific feedforward command learned for a speech unit (and generated by the synaptic projection from the speech sound map) but also by a feedback command generated at the level of the sensory error maps (see Fig. 4).
Learning (modeling speech acquisition)
While the structure of a neuroscientific model of speech processing (given in Fig. 4 for the DIVA model) is mainly determined by evolutionary processes, the (language-specific) knowledge as well as the (language-specific) speaking skills are learned and trained during speech acquisition. In the case of the DIVA model it is assumed that the newborn has not available an already structured (language-specific) speech sound map; i.e. no neuron within the speech sound map is related to any speech unit. Rather the organization of the speech sound map as well as the tuning of the projections to the motor map and to the sensory target region maps is learned or trained during speech acquisition. Two important phases of early speech acquisition are modeled in the DIVA approach: Learning by babbling and by imitation.
Babbling
During babbling the synaptic projections between sensory error maps and motor map are tuned. This training is done by generating an amount of semi-random feedforward commands, i.e. the DIVA model "babbles". Each of these babbling commands leads to the production of an "articulatory item", also labeled as "pre-linguistic (i.e. non language-specific) speech item" (i.e. the articulatory model generates an articulatory movement pattern on the basis of the babbling motor command). Subsequently an acoustic signal is generated.
On the basis of the articulatory and acoustic signal, a specific auditory and somatosensory state pattern is activated at the level of the sensory state maps (see Fig. 4) for each (pre-linguistic) speech item. At this point the DIVA model has available the sensory and associated motor activation pattern for different speech items, which enables the model to tune the synaptic projections between sensory error maps and motor map. Thus, during babbling the DIVA model learns feedback commands (i.e. how to produce a proper (feedback) motor command for a specific sensory input).
Imitation
During imitation the DIVA model organizes its speech sound map and tunes the synaptic projections between speech sound map and motor map - i.e. tuning of forward motor commands - as well as the synaptic projections between speech sound map and sensory target regions (see Fig. 4). Imitation training is done by exposing the model to an amount of acoustic speech signals representing realizations of language-specific speech units (e.g. isolated speech sounds, syllables, words, short phrases).
The tuning of the synaptic projections between speech sound map and auditory target region map is accomplished by assigning one neuron of the speech sound map to the phonemic representation of that speech item and by associating it with the auditory representation of that speech item, which is activated at the auditory target region map. Auditory regions (i.e. a specification of the auditory variability of a speech unit) occur, because one specific speech unit (i.e. one specific phonemic representation) can be realized by several (slightly) different acoustic (auditory) realizations (for the difference between speech item and speech unit see above: feedforward control) .
The tuning of the synaptic projections between speech sound map and motor map (i.e. tuning of forward motor commands) is accomplished with the aid of feedback commands, since the projections between sensory error maps and motor map were already tuned during babbling training (see above). Thus the DIVA model tries to "imitate" an auditory speech item by attempting to find a proper feedforward motor command. Subsequently the model compares the resulting sensory output (current sensory state following the articulation of that attempt) with the already learned auditory target region (intended sensory state) for that speech item. Then the model updates the current feedforward motor command by the current feedback motor command generated from the auditory error map of the auditory feedback system. This process may be repeated several times (several attempts). The DIVA model is capable of producing the speech item with a decreasing auditory difference between current and intended auditory state from attempt to attempt.
During imitation the DIVA model is also capable of tuning the synaptic projections from speech sound map to somatosensory target region map, since each new imitation attempt produces a new articulation of the speech item and thus produces a somatosensory state pattern which is associated with the phonemic representation of that speech item.
Perturbation experiments
Real-time perturbation of F1: the influence of auditory feedback
While auditory feedback is most important during speech acquisition, it may be activated less if the model has learned a proper feedforward motor command for each speech unit. But it has been shown that auditory feedback needs to be strongly coactivated in the case of auditory perturbation (e.g. shifting a formant frequency, Tourville et al. 2005).[10] This is comparable to the strong influence of visual feedback on reaching movements during visual perturbation (e.g. shifting the location of objects by viewing through a prism).
Unexpected blocking of the jaw: the influence of somatosensory feedback
In a comparable way to auditory feedback, also somatosensory feedback can be strongly coactivated during speech production, e.g. in the case of unexpected blocking of the jaw (Tourville et al. 2005).
ACT model
A further approach in neurocomputational modeling of speech processing is the ACT model developed by Bernd J. Kröger and his group[11] at RWTH Aachen University, Germany (Kröger et al. 2014,[12] Kröger et al. 2009,[13] Kröger et al. 2011[14]). The ACT model is in accord with the DIVA model in large parts. The ACT model focuses on the "action repository" (i.e. repository for sensorimotor speaking skills, comparable to the mental syllablary, see Levelt and Wheeldon 1994[15]), which is not spelled out in detail in the DIVA model. Moreover the ACT model explicitly introduces a level of motor plans, i.e. a high-level motor description for the production of speech items (see motor goals, motor cortex). The ACT model - like any neurocomputational model - remains speculative to some extent.
Structure

The organization or structure of the ACT model is given in Fig. 5.
For speech production, the ACT model starts with the activation of a phonemic representation of a speech item (phonemic map). In the case of a frequent syllable, a co-activation occurs at the level of the phonetic map, leading to a further co-activation of the intended sensory state at the level of the sensory state maps and to a co-activation of a motor plan state at the level of the motor plan map. In the case of an infrequent syllable, an attempt for a motor plan is generated by the motor planning module for that speech item by activating motor plans for phonetic similar speech items via the phonetic map (see Kröger et al. 2011[16]). The motor plan or vocal tract action score comprises temporally overlapping vocal tract actions, which are programmed and subsequently executed by the motor programming, execution, and control module. This module gets real-time somatosensory feedback information for controlling the correct execution of the (intended) motor plan. Motor programing leads to activation pattern at the level lof the primary motor map and subsequently activates neuromuscular processing. Motoneuron activation patterns generate muscle forces and subsequently movement patterns of all model articulators (lips, tongue, velum, glottis). The Birkholz 3D articulatory synthesizer is used in order to generate the acoustic speech signal.
Articulatory and acoustic feedback signals are used for generating somatosensory and auditory feedback information via the sensory preprocessing modules, which is forwarded towards the auditory and somatosensory map. At the level of the sensory-phonetic processing modules, auditory and somatosensory information is stored in short-term memory and the external sensory signal (ES, Fig. 5, which are activated via the sensory feedback loop) can be compared with the already trained sensory signals (TS, Fig. 5, which are activated via the phonetic map). Auditory and somatosensory error signals can be generated if external and intended (trained) sensory signals are noticeably different (cf. DIVA model).
The light green area in Fig. 5 indicates those neural maps and processing modules, which process a syllable as a whole unit (specific processing time window around 100 ms and more). This processing comprises the phonetic map and the directly connected sensory state maps within the sensory-phonetic processing modules and the directly connected motor plan state map, while the primary motor map as well as the (primary) auditory and (primary) somatosensory map process smaller time windows (around 10 ms in the ACT model).
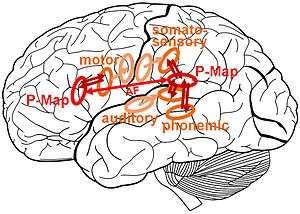
The hypothetical cortical location of neural maps within the ACT model is shown in Fig. 6. The hypothetical locations of primary motor and primary sensory maps are given in magenta, the hypothetical locations of motor plan state map and sensory state maps (within sensory-phonetic processing module, comparable to the error maps in DIVA) are given in orange, and the hypothetical locations for the mirrored phonetic map is given in red. Double arrows indicate neuronal mappings. Neural mappings connect neural maps, which are not far apart from each other (see above). The two mirrored locations of the phonetic map are connected via a neural pathway (see above), leading to a (simple) one-to-one mirroring of the current activation pattern for both realizations of the phonetic map. This neural pathway between the two locations of the phonetic map is assumed to be a part of the fasciculus arcuatus (AF, see Fig. 5 and Fig. 6).
For speech perception, the model starts with an external acoustic signal (e.g. produced by an external speaker). This signal is preprocessed, passes the auditory map, and leads to an activation pattern for each syllable or word on the level of the auditory-phonetic processing module (ES: external signal, see Fig. 5). The ventral path of speech perception (see Hickok and Poeppel 2007[17]) would directly activate a lexical item, but is not implemented in ACT. Rather, in ACT the activation of a phonemic state occurs via the phonemic map and thus may lead to a coactivation of motor representations for that speech item (i.e. dorsal pathway of speech perception; ibid.).
Action repository

The phonetic map together with the motor plan state map, sensory state maps (occurring within the sensory-phonetic processing modules), and phonemic (state) map form the action repository. The phonetic map is implemented in ACT as a self-organizing neural map and different speech items are represented by different neurons within this map (punctual or local representation, see above: neural representations). The phonetic map exhibits three major characteristics:
- More than one phonetic realization may occur within the phonetic map for one phonemic state (see phonemic link weights in Fig. 7: e.g. the syllable /de:m/ is represented by three neurons within the phonetic map)
- Phonetotopy: The phonetic map exhibits an ordering of speech items with respect to different phonetic features (see phonemic link weights in Fig. 7. Three examples: (i) the syllables /p@/, /t@/, and /k@/ occur in an upward ordering at the left side within the phonetic map; (ii) syllable-initial plosives occur in the upper left part of the phonetic map while syllable initial fricatives occur in the lower right half; (iii) CV syllables and CVC syllables as well occur in different areas of the phonetic map.).
- The phonetic map is hypermodal or multimodal: The activation of a phonetic item at the level of the phonetic map coactivates (i) a phonemic state (see phonemic link weights in Fig. 7), (ii) a motor plan state (see motor plan link weights in Fig. 7), (iii) an auditory state (see auditory link weights in Fig. 7), and (iv) a somatosensory state (not shown in Fig. 7). All these states are learned or trained during speech acquisition by tuning the synaptic link weights between each neuron within the phonetic map, representing a particular phonetic state and all neurons within the associated motor plan and sensory state maps (see also Fig. 3).
The phonetic map implements the action-perception-link within the ACT model (see also Fig. 5 and Fig. 6: the dual neural representation of the phonetic map in the frontal lobe and at the intersection of temporal lobe and parietal lobe).
Motor plans
A motor plan is a high level motor description for the production and articulation of a speech items (see motor goals, motor skills, articulatory phonetics, articulatory phonology). In our neurocomputational model ACT a motor plan is quantified as a vocal tract action score. Vocal tract action scores quantitatively determine the number of vocal tract actions (also called articulatory gestures), which need to be activated in order to produce a speech item, their degree of realization and duration, and the temporal organization of all vocal tract actions building up a speech item (for a detailed description of vocal tract actions scores see e.g. Kröger & Birkholz 2007).[18] The detailed realization of each vocal tract action (articulatory gesture) depends on the temporal organization of all vocal tract actions building up a speech item and especially on their temporal overlap. Thus the detailed realization of each vocal tract action within an speech item is specified below the motor plan level in our neurocomputational model ACT (see Kröger et al. 2011).[19]
Integrating sensorimotor and cognitive aspects: the coupling of action repository and mental lexicon
A severe problem of phonetic or sensorimotor models of speech processing (like DIVA or ACT) is that the development of the phonemic map during speech acquisition is not modeled. A possible solution of this problem could be a direct coupling of action repository and mental lexicon without explicitly introducing a phonemic map at the beginning of speech acquisition (even at the beginning of imitation training; see Kröger et al. 2011 PALADYN Journal of Behavioral Robotics).
Experiments: speech acquisition
A very important issue for all neuroscientific or neurocomputational approaches is to separate structure and knowledge. While the structure of the model (i.e. of the human neuronal network, which is needed for processing speech) is mainly determined by evolutionary processes, the knowledge is gathered mainly during speech acquisition by processes of learning. Different learning experiments were carried out with the model ACT in order to learn (i) a five-vowel system /i, e, a, o, u/ (see Kröger et al. 2009), (ii) a small consonant system (voiced plosives /b, d, g/ in combination with all five vowels acquired earlier as CV syllables (ibid.), (iii) a small model language comprising the five-vowel system, voiced and unvoiced plosives /b, d, g, p, t, k/, nasals /m, n/ and the lateral /l/ and three syllable types (V, CV, and CCV) (see Kröger et al. 2011)[20] and (iv) the 200 most frequent syllables of Standard German for a 6 year old child (see Kröger et al. 2011).[21] In all cases, an ordering of phonetic items with respect to different phonetic features can be observed.
Experiments: speech perception
Despite the fact that the ACT model in its earlier versions was designed as a pure speech production model (including speech acquisition), the model is capable of exhibiting important basic phenomena of speech perception, i.e. categorical perception and the McGurk effect. In the case of categorical perception, the model is able to exhibit that categorical perception is stronger in the case of plosives than in the case of vowels (see Kröger et al. 2009). Furthermore the model ACT was able to exhibit the McGurk effect, if a specific mechanism of inhibition of neurons of the level of the phonetic map was implemented (see Kröger and Kannampuzha 2008).[22]
See also
| Wikimedia Commons has media related to Neurocomputational speech processing. |
- Speech production
- Speech perception
- Computational neuroscience
- Theoretical neuroscience
- Articulatory synthesis
- auditory feedback
References
- ↑ Rouat J, Loiselle S, Pichevar R (2007) Towards neurocomputational speech and sound processing. In: Sytylianou Y, Faundez-Zanuy M, Esposito A. Progress in Nonlinear Speech Processing (Springer, Berlin) pp. 58-77. ACMDL
- ↑ Ardi Roelofs
- ↑ WEAVER++
- ↑ Hinton GE, McClelland JL, Rumelhart DE (1968) Distributed representations. In: Rumelhart DE, McClelland JL (eds.). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Volume 1: Foundations (MIT Press, Cambridge, MA)
- ↑ DIVA model: a model of speech production, focussing on feedback control processes, developed by Frank H. Guenther and his group at Boston University, MA, USA. The term "DIVA" refers to "Directions Into Velocities of Articulators"
- ↑ Guenther, F.H., Ghosh, S.S., and Tourville, J.A. (2006) pdf. Neural modeling and imaging of the cortical interactions underlying syllable production. Brain and Language, 96, pp. 280–301
- ↑ Guenther FH (2006) Cortical interaction underlying the production of speech sounds. Journal of Communication Disorders 39, 350–365
- ↑ Guenther, F.H., and Perkell, J.S. (2004) pdf. A neural model of speech production and its application to studies of the role of auditory feedback in speech. In: B. Maassen, R. Kent, H. Peters, P. Van Lieshout, and W. Hulstijn (eds.), Speech Motor Control in Normal and Disordered Speech (pp. 29–49). Oxford: Oxford University Press
- ↑ Guenther, F.H., Hampson, M., and Johnson, D. (1998) A theoretical investigation of reference frames for the planning of speech movements. Psychological Review 105: 611-633
- ↑ Tourville J, Guenther F, Ghosh S, Reilly K, Bohland J, Nieto-Castanon A (2005) Effects of acoustic and articulatory perturbation on cortical activity during speech production. Poster, 11th annual meeting of the Organization of Human Brain Mapping (Toronto, Canada)
- ↑ ACT model: A model of speech production, perception, and acquisition, developed by Bernd J. Kröger and his group at RWTH Aachen University, Germany. The term "ACT" refers to the term "ACTion"
- ↑ BJ Kröger, J Kannampuzha, E Kaufmann (2014) pdf Associative learning and self-organization as basic principles for simulating speech acquisition, speech production, and speech perception. EPJ Nonlinear Biomedical Physics 2 (1), 1-28
- ↑ Kröger BJ, Kannampuzha J, Neuschaefer-Rube C (2009) pdf Towards a neurocomputational model of speech production and perception. Speech Communication 51: 793-809
- ↑ Kröger BJ, Birkholz P, Neuschaefer-Rube C (2011) Towards an articulation-based developmental robotics approach for word processing in face-to-face communication. PALADYN Journal of Behavioral Robotics 2: 82-93. DOI
- ↑ Levelt, W.J.M., Wheeldon, L. (1994) Do speakers have access to a mental syllabary? Cognition 50, 239–269
- ↑ Kröger BJ, Miller N, Lowit A, Neuschaefer-Rube C. (2011) Defective neural motor speech mappings as a source for apraxia of speech: Evidence from a quantitative neural model of speech processing. In: Lowit A, Kent R (eds.) Assessment of Motor Speech Disorders. (Plural Publishing, San Diego, CA) pp. 325-346
- ↑ Hickok G, Poeppel D (2007) Towards a functional neuroanatomy of speech perception. Trends in Cognitive Sciences 4, 131–138
- ↑ Kröger BJ, Birkholz P (2007) A gesture-based concept for speech movement control in articulatory speech synthesis. In: Esposito A, Faundez-Zanuy M, Keller E, Marinaro M (eds.) Verbal and Nonverbal Communication Behaviours, LNAI 4775 (Springer Verlag, Berlin, Heidelberg) pp. 174-189
- ↑ Kröger BJ, Birkholz P, Kannampuzha J, Eckers C, Kaufmann E, Neuschaefer-Rube C (2011) Neurobiological interpretation of a quantitative target approximation model for speech actions. In: Kröger BJ, Birkholz P (eds.) Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung 2011 (TUDpress, Dresden, Germany), pp. 184-194
- ↑ Kröger BJ, Miller N, Lowit A, Neuschaefer-Rube C. (2011) Defective neural motor speech mappings as a source for apraxia of speech: Evidence from a quantitative neural model of speech processing. In: Lowit A, Kent R (eds.) Assessment of Motor Speech Disorders. (Plural Publishing, San Diego, CA) pp. 325-346
- ↑ Kröger BJ, Birkholz P, Kannampuzha J, Kaufmann E, Neuschaefer-Rube C (2011) Towards the acquisition of a sensorimotor vocal tract action repository within a neural model of speech processing. In: Esposito A, Vinciarelli A, Vicsi K, Pelachaud C, Nijholt A (eds.) Analysis of Verbal and Nonverbal Communication and Enactment: The Processing Issues. LNCS 6800 (Springer, Berlin), pp. 287-293
- ↑ Kröger BJ, Kannampuzha J (2008) A neurofunctional model of speech production including aspects of auditory and audio-visual speech perception. Proceedings of the International Conference on Audio-Visual Speech Processing 2008 (Moreton Island, Queensland, Australia) pp. 83–88