Micro-operation
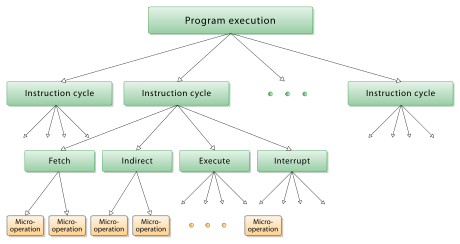
In computer central processing units, micro-operations (also known as a micro-ops or μops) are detailed low-level instructions used in some designs to implement complex machine instructions (sometimes termed macro-instructions in this context).[2]:8–9
Usually, micro-operations perform basic operations on data stored in one or more registers, including transferring data between registers or between registers and external buses of the central processing unit (CPU), and performing arithmetic or logical operations on registers. In a typical fetch-decode-execute cycle, each step of a macro-instruction is decomposed during its execution so the CPU determines and steps through a series of micro-operations. The execution of micro-operations is performed under control of the CPU's control unit, which decides on their execution while performing various optimizations such as reordering, fusion and caching.[1]
Optimizations
Various forms of μops have long been the basis for traditional microcode routines used to simplify the implementation of a particular CPU design or perhaps just the sequencing of certain multi-step operations or addressing modes. More recently, μops have also been employed in a different way in order to let modern CISC processors more easily handle asynchronous parallel and speculative execution: As with traditional microcode, one or more table lookups (or equivalent) is done to locate the appropriate μop-sequence based on the encoding and semantics of the machine instruction (the decoding or translation step), however, instead of having rigid μop-sequences controlling the CPU directly from a microcode-ROM, μops are here dynamically buffered for rescheduling before being executed.[3]:6–7, 9–11
This buffering means that the fetch and decode stages can be more detached from the execution units than is feasible in a more traditional microcoded (or hard-wired) design. As this allows a degree of freedom regarding execution order, it makes some extraction of instruction level parallelism out of a normal single-threaded program possible (provided that dependencies are checked etc.). It opens up for more analysis and therefore also for reordering of code sequences in order to dynamically optimize mapping and scheduling of μops onto machine resources (such as ALUs, load/store units etc.). As this happens on the μop-level, sub-operations of different machine (macro) instructions may often intermix in a particular μop-sequence, forming partially reordered machine instructions as a direct consequence of the out-of-order dispatching of microinstructions from several macro instructions. However, this is not the same as the micro-op fusion, which aims at the fact that a more complex microinstruction may replace a few simpler microinstructions in certain cases, typically in order to minimize state changes and usage of the queue and reorder buffer space, therefore reducing power consumption. Micro-op fusion is used in some modern CPU designs.[2]:89–91, 105–106[3]:6–7, 9–15
Execution optimization has gone even further; processors not only translate many machine instructions into a series of μops, but also do the opposite when appropriate; they combine certain machine instruction sequences (such as a compare followed by a conditional jump) into a more complex μop which fits the execution model better and thus can be executed faster or with less machine resources involved. This is also known as macro-op fusion.[2]:106–107[3]:12–13
Another way to try to improve performance is to cache the decoded micro-operations, so that if the same macroinstruction is executed again, the processor can directly access the decoded micro-operations from a special cache, instead of decoding them again. The Execution Trace Cache found in Intel NetBurst microarchitecture (Pentium 4) is a widespread example of this technique.[4] The size of this cache may be stated in terms of how many thousands of micro-operations it can store: kμops.[5]
See also
References
- 1 2 "Computer Organization and Architecture, Chapter 15. Control Unit Operation" (PDF). umcs.maine.edu. 2010-03-16. Retrieved 2014-12-29.
- 1 2 3 Agner Fog (2014-02-19). "The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers" (PDF). agner.org. Retrieved 2014-03-21.
- 1 2 3 Michael E. Thomadakis (2011-03-17). "The Architecture of the Nehalem Processor and Nehalem-EP SMP Platforms" (PDF). Texas A&M University. Retrieved 2014-03-21.
- ↑ "Intel Pentium 4 1.4GHz & 1.5GHz". AnandTech. 2000-11-20. Retrieved 2013-10-06.
- ↑ Baruch Solomon; Avi Mendelson; Doron Orenstein; Yoav Almog; Ronny Ronen (August 2001). "Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA" (PDF). Intel. doi:10.1109/LPE.2001.945363. Retrieved 2014-03-21.