Mediation-driven attachment (MDA) model
Barabasi and Albert in 1999 noted through their seminal paper [1] noted that (i) most natural and man-made networks are not static, rather they grow with time and (ii) new nodes do not connect with an already connected one randomly rather preferentially with respect to their degrees. The later mechanism is called preferential attachment (PA) rule which embodies the rich get richer phenomena in economics. In their first model, known as the Barabási–Albert model, Barabási and Albert (BA model) choose

where, is the probability that the new node picks a node from the labelled nodes of the existing network. It directly embodies the rich get richer mechanism.


Recently, Hassan et al. proposed a mediation-driven attachment (MDA) model which appear to embodies the PA rule but not directly rather in disguise.[2] In the MDA model, an incoming node choose an existing node to connect by first picking one of the existing nodes at random which is regarded as mediator. The new node then connect with one of the neighbors of the mediator which is also picked at random. Now the question is: What is the probability that an already existing node is finally picked to connect it with the new node? Say, the node has degree and hence it has neighbors. Consider that the neighbors of are labeled which have degrees respectively. One can reach the node from each of these nodes with probabilities inverse of their respective degrees, and each of the nodes are likely to be picked at random with probability . Thus the probability of the MDA model is:




![{\displaystyle \Pi (i)={\frac {1}{N}}{\Big [}{\frac {1}{k_{1}}}+{\frac {1}{k_{2}}}+...+{\frac {1}{k_{k_{i}}}}{\Big ]}={\frac {\sum _{j=1}^{k_{i}}{\frac {1}{k_{j}}}}{N}}.}](../I/m/4b635f666de3706b499de73625649f4a84b5eb99.svg)
It can be re-written as

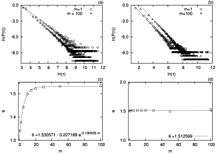
where the factor is the inverse of the harmonic mean (IHM) of degrees of the neighbors of the node . Extensive numerical simulation suggest that for small the IHM value of each node fluctuate so wildly that the mean of the IHM values over the entire network bears no meaning. However, for large (specially approximately greater than 14) the IHM value assumes a becomes constant value in the large limit. In this limit which is exactly the PA rule. It implies that the higher the links (degree) a node has, the higher its chance of gaining more links since they can be reached in a larger number of ways through mediators which essentially embodies the intuitive idea of rich get richer mechanism. Therefore, the MDA network can be seen to follow the PA rule but in disguise. Moreover, for small the MFA is no longer valid rather the attachment probability becomes super-preferential in character.




Degree distribution: The two factors that the mean of the IHM is meaningful and it is independent of implies that one can apply the mean-field approximation (MFA). That is, within this approximation one can replace the true IHM value of each node by their mean, where the factor that the number of edges the new nodes come with is introduced for latter convenience. The rate equation to solve then becomes exactly like that of the BA model and hence the network that emerges following MDA rule is also scale-free in nature. The only difference is that the exponent depends on where as in the BA model independent of .




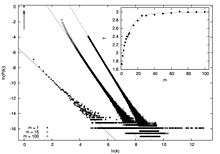
Leadership persistence probability: In the growing network not all nodes are equally important. The extent of their importance is measured by the value of their degree . Nodes which are linked to an unusually large number of other nodes, i.e. nodes with exceptionally high value, are known as hubs. They are special because their existence make the mean distance, measured in units of the number of links, between nodes incredibly small thereby playing the key role in spreading rumors, opinions, diseases, computer viruses etc.[3] It is, therefore, important to know the properties of the largest hub, which we regard as the leader. Like in society, the leadership in a growing network is not permanent. That is, once a node becomes the leader, it does not mean that it remains the leader ad infinitum. An interesting question is: how long does the leader retain this leadership property as the network evolves? To find an answer to this question, we define the leadership persistence probability that aleader retains its leadership for at least up to time . Persistence probability has been of interest in many different systems ranging from coarsening dynamics to fluctuating interfaces or polymer chains.



The basic idea of the MDA rule is, however not completely new as either this or models similar to this can be found in a few earlier works, albeit their approach, ensuing analysis and their results are different from ours. For instance, Saramaki and Kaski presented a random-walk based model.[4] Another model proposed by Boccaletti et al. may appear similar to ours, but it markedly differs on closer look.[5] Recently, Yang {\it et al.} too gave a form for and resorted to mean-field approximation.[6] However, the nature of their expressions are significantly different from the one studied by Hassan et al.. Yet another closely related model is the Growing Network with Redirection (GNR) model presented by Gabel, Krapivsky and Redner where at each time step a new node either attaches to a randomly chosen target node with probability , or to the parent of the target with probability .[7] The GNR model with may appear similar to the MDA model. However, it should be noted that unlike the GNR model, the MDA model is for undirected networks, and that the new link can connect with any neighbor of the mediator- parent or not. One more difference is that, in the MDA model new node may join the existing network with edges and in the GNR model it is considered case only.



References
- ↑ A. -L. Barab\'{a}si and R. Albert, Science 286 509 (1999)
- ↑ M. K. Hassan, Liana Islam and Syed Arefinul Haque, Degree distribution, rank-size distribution, and leadership persistence in mediation-driven attachment networks Physica A 469 23 (2017) http://dx.doi.org/10.1016/j.physa.2016.11.001
- ↑ R. Pastor-Satorras, A. Vespignani., Phys. Rev. Lett. 86 3200 (2001).
- ↑ Saramaki and K. Kaski, Physica A 341, 80 (2004)
- ↑ S. Boccaletti, D.-U. Hwang and V. Latora, I. J. Bifurcation and Chaos 17 2447 (2007)
- ↑ X. -H. Yang, S. -L. Lou, G. Chen, S. -Y. Chen, W. Huang, Physica A 392 3531 (2013).
- ↑ P. L. Krapivsky and S. Redner, Phys. Rev. E 63, 066123 (2001)