Interlingual machine translation

Interlingual machine translation is one of the classic approaches to machine translation. In this approach, the source language, i.e. the text to be translated is transformed into an interlingua, i.e., an abstract language-independent representation. The target language is then generated from the interlingua. Within the rule-based machine translation paradigm, the interlingual approach is an alternative to the direct approach and the transfer approach.
In the direct approach, words are translated directly without passing through an additional representation. In the transfer approach the source language is transformed into an abstract, less language-specific representation. Linguistic rules which are specific to the language pair then transform the source language representation into an abstract target language representation and from this the target sentence is generated.
The interlingual approach to machine translation has advantages and disadvantages. The advantages are that it requires fewer components in order to relate each source language to each target language, it takes fewer components to add a new language, it supports paraphrases of the input in the original language, it allows both the analysers and generators to be written by monolingual system developers, and it handles languages that are very different from each other (e.g. English and Arabic[1]). The obvious disadvantage is that the definition of an interlingua is difficult and maybe even impossible for a wider domain. The ideal context for interlingual machine translation is thus multilingual machine translation in a very specific domain.
History
The first ideas about interlingual machine translation appeared in the 17th century with Descartes and Leibniz, who came up with theories of how to create dictionaries using universal numerical codes. Others, such as Cave Beck, Athanasius Kircher and Johann Joachim Becher worked on developing an unambiguous universal language based on the principles logic and iconographs. In 1668, John Wilkins described his interlingua in his "Essay towards a Real Character and a Philosophical Language". In the 18th and 19th centuries many proposals for "universal" international languages were developed, the most well known being Esperanto.
That said, applying the idea of a universal language to machine translation did not appear in any of the first significant approaches. Instead, work started on pairs of languages. However, during the 1950s and 60s, researchers in Cambridge headed by Margaret Masterman, in Leningrad headed by Nikolai Andreev and in Milan by Silvio Ceccato started work in this area. The idea was discussed extensively by the Israeli philosopher Yehoshua Bar-Hillel in 1969.
During the 1970s, noteworthy research was done in Grenoble by researchers attempting to translate physics and mathematical texts from Russian to French, and in Texas a similar project (METAL) was ongoing for Russian to English. Early interlingual MT systems were also built at Stanford in the 1970s by Roger Schank and Yorick Wilks; the former became the basis of a commercial system for the transfer of funds, and the latter's code is preserved at The Computer Museum at Boston as the first interlingual machine translation system.
In the 1980s, renewed relevance was given to interlingua-based, and knowledge-based approaches to machine translation in general, with much research going on in the field. The uniting factor in this research was that high-quality translation required abandoning the idea of requiring total comprehension of the text. Instead, the translation should be based on linguistic knowledge and the specific domain in which the system would be used. The most important research of this era was done in distributed language translation (DLT) in Utrecht, which worked with a modified version of Esperanto, and the Fujitsu system in Japan.
Outline
In this method of translation, the interlingua can be thought of as a way of describing the analysis of a text written in a source language such that it is possible to convert its morphological, syntactic, semantic (and even pragmatic) characteristics, that is "meaning" into a target language. This interlingua is able to describe all of the characteristics of all of the languages which are to be translated, instead of simply translating from one language to another.
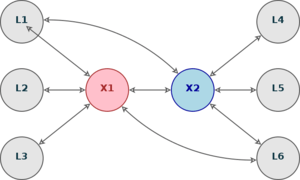
Sometimes two interlinguas are used in translation. It is possible that one of the two covers more of the characteristics of the source language, and the other possess more of the characteristics of the target language. The translation then proceeds by converting sentences from the first language into sentences closer to the target language through two stages. The system may also be set up such that the second interlingua uses a more specific vocabulary that is closer, or more aligned with the target language, and this could improve the translation quality.
The above-mentioned system is based on the idea of using linguistic proximity to improve the translation quality from a text in one original language to many other structurally similar languages from only one original analysis. This principle is also used in pivot machine translation, where a natural language is used as a "bridge" between two more distant languages. For example, in the case of translating to English from Ukrainian using Russian as an intermediate language.[2]
Translation process
In interlingual machine translation systems, there are two monolingual components: the analysis of the source language and the interlingual, and the generation of the interlingua and the target language. It is however necessary to distinguish between interlingual systems using only syntactic methods (for example the systems developed in the 1970s at the universities of Grenoble and Texas) and those based on artificial intelligence (from 1987 in Japan and the research at the universities of Southern California and Carnegie Mellon). The first type of system corresponds to that outlined in Figure 1. while the other types would be approximated by the diagram in Figure 4.
The following resources are necessary to an interlingual machine translation system:

- Dictionaries (or lexicons) for analysis and generation (specific to the domain and the languages involved).
- A conceptual lexicon (specific to the domain), which is the knowledge base about events and entities known in the domain.
- A set of projection rules (specific to the domain and the languages).
- Grammars for the analysis and generation of the languages involved.
One of the problems of knowledge-based machine translation systems is that it becomes impossible to create databases for domains larger than very specific areas. Another is that processing these databases is very computationally expensive.
Efficacy
One of the main advantages of this strategy is that it provides an economical way to make multilingual translation systems. With an interlingua it becomes unnecessary to make a translation pair between each pair of languages in the system. So instead of creating language pairs, where is the number of languages in the system, it is only necessary to make pairs between the languages and the interlingua.



The main disadvantage of this strategy is the difficulty of creating an adequate interlingua. It should be both abstract and independent of the source and target languages. The more languages added to the translation system, and the more different they are, the more potent the interlingua must be to express all possible translation directions. Another problem is that it is difficult to extract meaning from texts in the original languages to create the intermediate representation.
Existing interlingual machine translation systems
See also
Notes
- ↑ Abdel Monem, A., Shaalan, K., Rafea, A., Baraka, H., Generating Arabic Text in Multilingual Speech-to-Speech Machine Translation Framework, Machine Translation, Springer, Netherlands, 20(4): 205-258, December 2008.
- ↑ Bogdan Babych, Anthony Hartley, and Serge Sharoff (2007) "Translating from under-resourced languages: comparing direct transfer against pivot translation". Proceedings of MT Summit XI, 10–14 September 2007, Copenhagen, Denmark. pp.29--35