Degree of anonymity
In anonymity networks (e.g., Tor, Crowds, Mixmaster, I2P, etc.), it is important to be able to measure quantitatively the guarantee that is given to the system. The degree of anonymity is a device that was proposed at the 2002 Privacy Enhancing Technology (PET) conference. There were two papers that put forth the idea of using entropy as the basis for formally measuring anonymity: "Towards an Information Theoretic Metric for Anonymity", and "Towards Measuring Anonymity". The ideas presented are very similar with minor differences in the final definition of .

Background
Anonymity networks have been developed and many have introduced methods of proving the anonymity guarantees that are possible, originally with simple Chaum Mixes and Pool Mixes the size of the set of users was seen as the security that the system could provide to a user. This had a number of problems; intuitively if the network is international then it is unlikely that a message that contains only Urdu came from the United States, and vice versa. Information like this and via methods like the predecessor attack and intersection attack helps an attacker increase the probability that a user sent the message.
Example With Pool Mixes
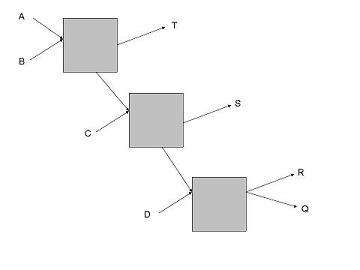 As an example consider the network shown above, in here and are users (senders), , and are servers (receivers), the boxes are mixes, and , and where denotes the anonymity set. Now as there are pool mixes let the cap on the number of incoming messages to wait before sending be ; as such if , or is communicating with and receives a message then knows that it must have come from ???? (as the links between the mixes can only have message at a time). This is in no way reflected in 's anonymity set, but should be taken into account in the analysis of the network.
As an example consider the network shown above, in here and are users (senders), , and are servers (receivers), the boxes are mixes, and , and where denotes the anonymity set. Now as there are pool mixes let the cap on the number of incoming messages to wait before sending be ; as such if , or is communicating with and receives a message then knows that it must have come from ???? (as the links between the mixes can only have message at a time). This is in no way reflected in 's anonymity set, but should be taken into account in the analysis of the network.















Degree of Anonymity
The degree of anonymity takes into account the probability associated with each user, it begins by defining the entropy of the system (here is where the papers differ slightly but only with notation, we will use the notation from .):
,
where is the entropy of the network, is the number of nodes in the network, and is the probability associated with node .
Now the maximal entropy of a network occurs when there is uniform probability associated with each node and this yields .
The degree of anonymity (now the papers differ slightly in the definition here, defines a bounded degree where it is compared to and gives an unbounded definition—using the entropy directly, we will consider only the bounded case here) is defined as
.
Using this anonymity systems can be compared and evaluated using a quantitatively analysis.
![H(X):=\sum _{{i=1}}^{{N}}\left[p_{i}\cdot \lg \left({\frac {1}{p_{i}}}\right)\right]](../I/m/5e2415cfdd56662ee2057ab689e7856db507e4c7.svg)








Definition of Attacker
These papers also served to give concise definitions of an attacker:
- Internal/External
- an internal attacker controls nodes in the network, whereas an external can only compromise communication channels between nodes.
- Passive/Active
- an active attacker can add, remove, and modify any messages, whereas a passive attacker can only listen to the messages.
- Local/Global
- a local attacker has access to only part of the network, whereas a global can access the entire network.
Example
In the papers there are a number of example calculations of ; we will walk through some of them here.
Crowds
In Crowds there is a global probability of forwarding (), which is the probability a node will forward the message internally instead of routing it to the final destination. Let there be corrupt nodes and total nodes. In Crowds the attacker is internal, passive, and local. Trivially , and overall the entropy is , is this value divided by .


![H(x)\gets {\frac {N-p_{f}\cdot (N-C-1)}{N}}\cdot \lg \left[{\frac {N}{N-p_{f}\cdot (N-C-1)}}\right]+p_{f}\cdot {\frac {N-C-1}{N}}\cdot \lg \left[N/p_{f}\right]](../I/m/4a7b82d1114d811d521d3eeaeafa46184b52fd9f.svg)
Onion routing
In onion routing let's assume the attacker can exclude a subset of the nodes from the network, then the entropy would easily be , where is the size of the subset of non-excluded nodes. Under an attack model where a node can both globally listen to message passing and is a node on the path this decreases to , where is the length of the onion route (this could be larger or smaller than ), as there is no attempt in onion routing to remove the correlation between the incoming and outgoing messages.



Applications of this metric
In 2004, Diaz, Sassaman, and DeWitte presented an analysis of two anonymous remailers using the Serjantov and Danezis metric, showing one of them to provide zero anonymity under certain realistic conditions.
See also
References
- ^ See Towards Measuring Anonymity Claudia Diaz and Stefaan Seys and Joris Claessens and Bart Preneel (April 2002). Roger Dingledine and Paul Syverson, ed. "Towards measuring anonymity". Proceedings of Privacy Enhancing Technologies Workshop (PET 2002). Springer-Verlag, LNCS 2482. Archived from the original (– Scholar search) on July 10, 2006. Retrieved 2005-11-10.
- ^ See Towards an Information Theoretic Metric for Anonymity Andrei Serjantov and George Danezis (April 2002). Roger Dingledine and Paul Syverson, ed. "Towards an Information Theoretic Metric for Anonymity". Proceedings of Privacy Enhancing Technologies Workshop (PET 2002). Springer-Verlag, LNCS 2482. Archived from the original on July 19, 2004. Retrieved 2005-11-10.
- ^ See Comparison Between Two Practical Mix Designs Claudia Diaz and Len Sassaman and Evelyn Dewitte (September 2004). Dieter Gollmann, ed. "Comparison Between Two Practical Mix Designs" (PDF). Proceedings of European Symposium on Research in Computer Security (ESORICS 2004). Springer-Verlag, LNCS 3193. Retrieved 2008-06-06.